系统配置
语音识别
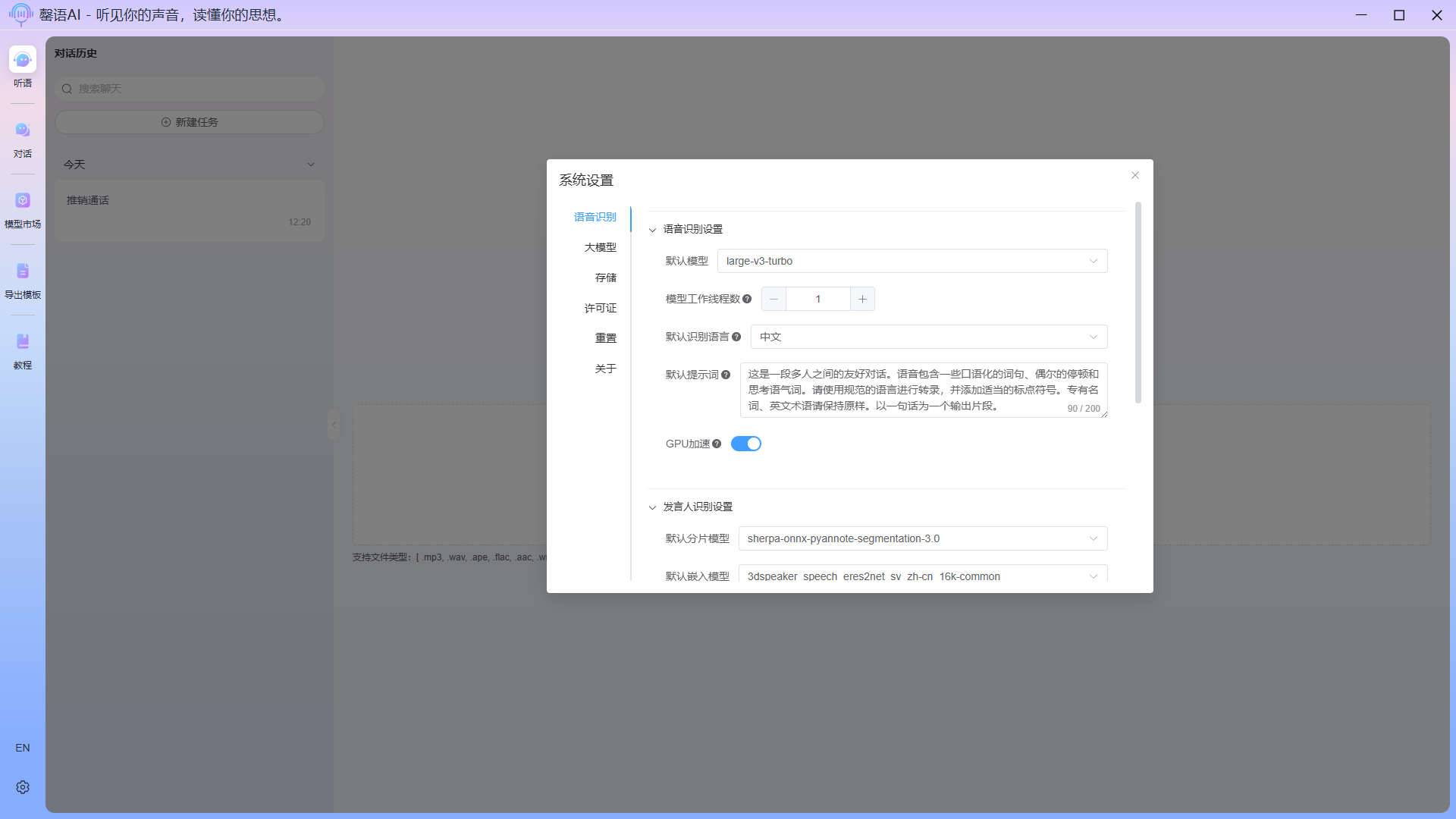
配置项说明:
- 语音识别设置:
- 默认模型:在语音识别中,默认使用的音频转文本模型。
- 模型工作线程数:识别任务中,启用的线程数,值不能大于CPU核心数,否则设备会有明显卡顿现象。在未开启GPU加速的情况下生效。
- 默认识别语言:在语音识别中,默认设置识别的语言种类。
- 默认提示词:在语音识别中,默认使用的提示词。
- GPU加速:开启GPU加速,可大幅度提升语音识别的效率,需要设备支持vulkan。
- 发言人识别设置:
- 默认分片模型:在发言人识别中,默认使用的音频切分模型。
- 默认嵌入模型:在发言人识别中,默认使用的音频向量化模型。
- 分片模型工作线程数:在切分音频任务中,程序执行任务使用的线程数量。对于大多数任务,设置 1或2 即可。
- 嵌入模型工作线程数:在音频向量化任务中,程序执行任务使用的线程数量。此为发言人识别中的耗时操作,建议调大一些,但总工作线程数不能大于CPU核心数,否则设备会有明显卡顿现象。总工作线程数 = 语音识别工作线程数 + 分片模型工作线程数 + 嵌入模型工作线程数
- 语音片段最短持续时间(秒):分片模型过滤语音片段的最短持续时间,低于此值的音频片段会被过滤掉。不建议设置过大的值,0.2-0.5即可。
- 静音片段最短持续时间(秒):分片模型过滤静音片段的最短持续时间,低于此值的静音片段会被填充或忽略。不建议设置过大的值,0.3-0.8即可。
- 语音激活阈值:此项设置为区分有效语音与背景噪声的阈值,建议设置0.7-0.95即可。
- 智能优化设置:
- 默认优化模型:在智能优化语音识别后的原始内容时,所使用的模型。
TIP
在 语音识别 里,提示词的作用方式和 ChatGPT 完全不同。它不是“指令”,而是给模型看的前文范例。模型会尽量模仿提示词的风格、词汇和格式来生成后续文本。了解了这个原理,才能写出真正好使的提示词。 下面这几条技巧可以帮助您写出更好更稳定的提示词。
技巧一:用“前文描述”,别用“指令列表”
语音识别 不是一个聊天机器人,它不理解“请帮我做……”、“遵循以下规则:1.……2.……”。它只会顺着你给的文字风格往下续写。
不好使的写法(祈使句)
规则:必须加标点。不要漏掉英文术语。每句换行。
好使的写法(前文故事/描述)
这是一段关于技术分享的语音。转录时使用了规范的标点符号。所有英文术语保持原样。每个句子单独成行。
技巧二:用提示词纠正专有名词和生僻词
如果音频里经常出现特定人名、产品名、专业术语,把它们自然地写进提示词里,能显著降低错误率。
例如,音频在讲 新文科,模型容易听成 新闻科:
- 提示词
本次演讲将介绍 新文科 的发展与成果。
这样模型在遇到类似发音时,会优先考虑 新文科 这个写法。
技巧三:用“软约束”控制输出格式
你希望转录结果怎么呈现,就在提示词里“演”出来。常见需求有:
- 逐句分段:在描述结尾加上“以一句话为一个输出片段”,或直接在提示词里分成短行。
- 加标点:提示词本身要带有规范标点,并写明“使用规范的标点符号”。
- 保英文:写明“英文术语和专有名词保持原样,不翻译”。
示例(模拟输出格式)
这是一段对话转录。 每个句子都单独成为一行。 所有标点都已规范添加。 术语如 API、GPU 保持原样。
技巧四:用“场景标签”引导整体风格
提示词开头的场景描述,会像滤镜一样影响模型的选词和语气。比较下面两种:
正式演讲
这是一场学术报告,语言严谨、书面化。
日常闲聊
这是一段朋友间的闲聊,语气轻松随意,偶尔有笑声。
同样一句话,前面的场景描述会让转录的文字更严肃还是更口语化。你那条通用提示词写“可能包含单人演讲或多人对话”,就是为了不偏向任何一方,保持中性。
技巧五:修正顽固错误(听错词)
如果某些词总是被听错,可以在提示词中“不经意地”示范正确写法。
例如,音频在讲 stable diffusion,总被识别成 stable defusion:
- 在提示词中加入
我们最近研究了 Stable Diffusion 模型的推理优化。
模型看到这个上下文,后续遇到类似发音时就更可能用 Diffusion。
技巧六:简短,别写小作文
提示词太长会挤占音频内容的上下文窗口,反而让后面的转录质量下降。一般建议控制在 200 个 token 以内(约一两句话到一小段),把最关键的格式和术语放进去即可。
技巧七:语言要和音频一致
如果音频是中文,提示词也用中文描述;音频是英文,提示词就用英文。中英混杂的提示词容易让模型在语言切换时出错。专有名词可以原样保留,但框架描述要统一语言。
速查模板
用户可以直接套用这个结构来写自己的提示词:
[场景描述],语音可能包含[口语/正式/技术分享]等内容。转录时使用了规范的标点符号,专有名词如 XXX、YYY 保持原样。以一句话为一个输出片段。例如:
这是一段产品评审会录音,可能包含多人讨论。语音带有口语化表达和短暂停顿。转录时使用规范标点,产品代号 T6、术语 UED 保持原样。以一句话为一个输出片段。
大模型
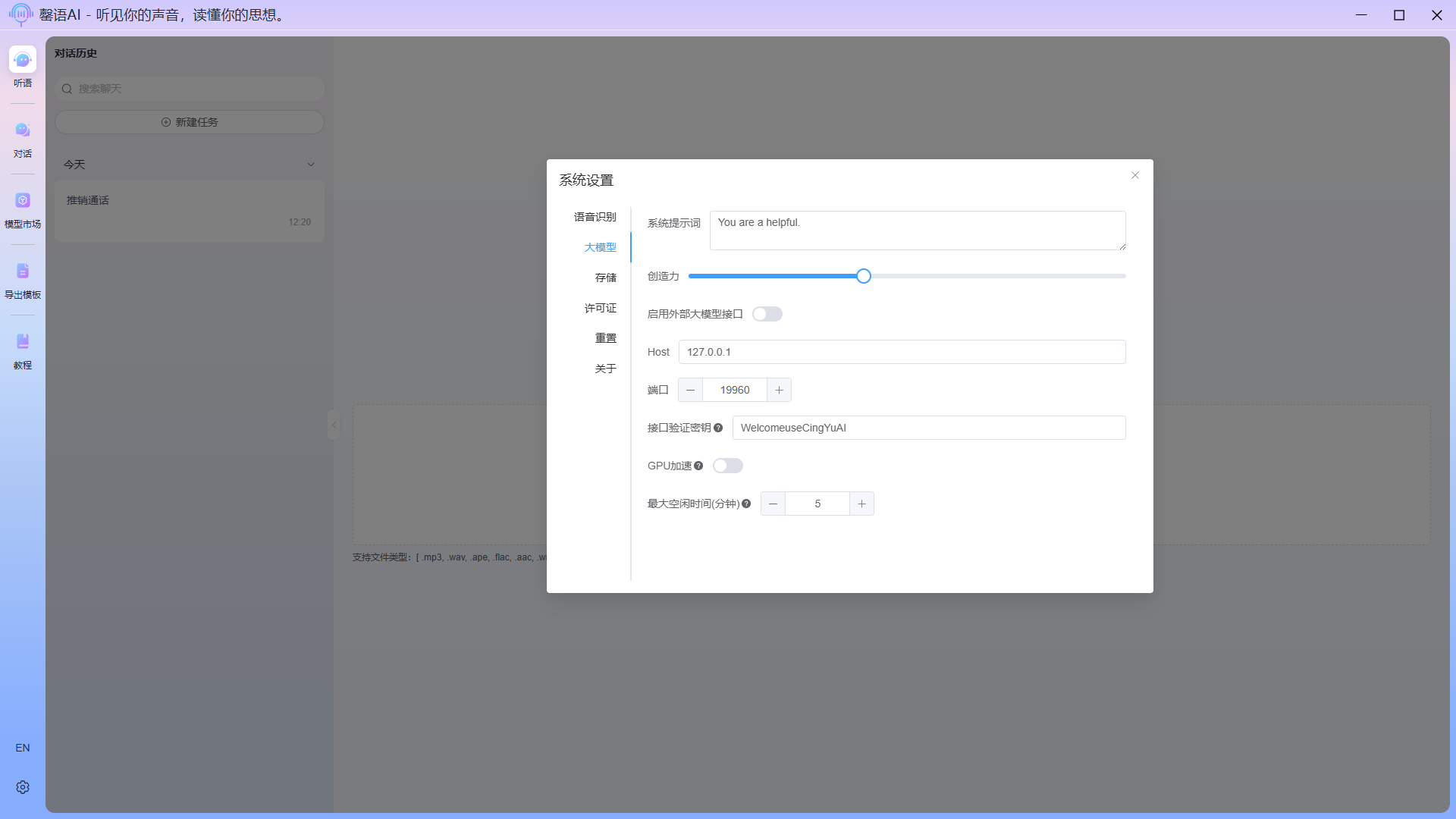
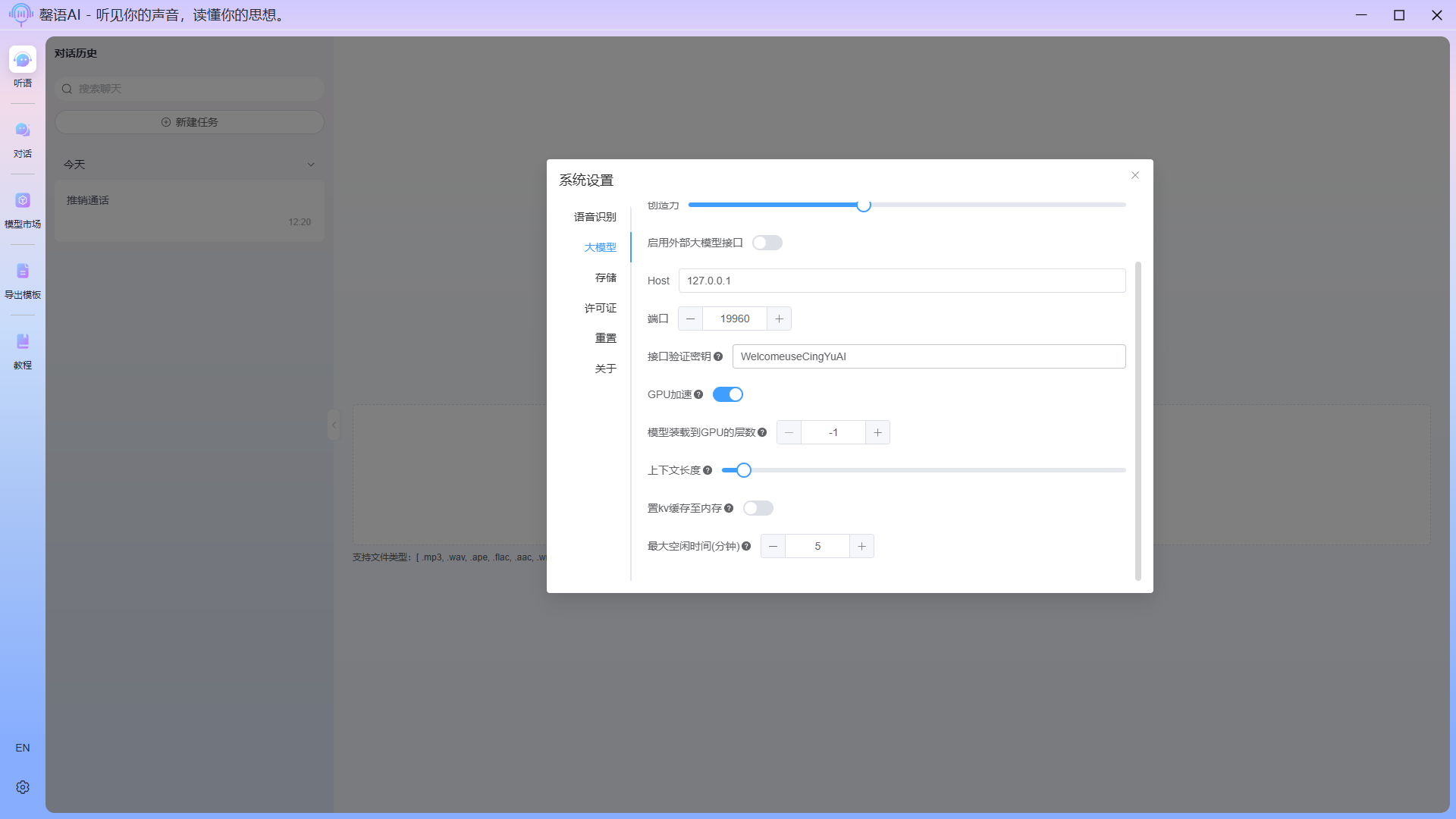
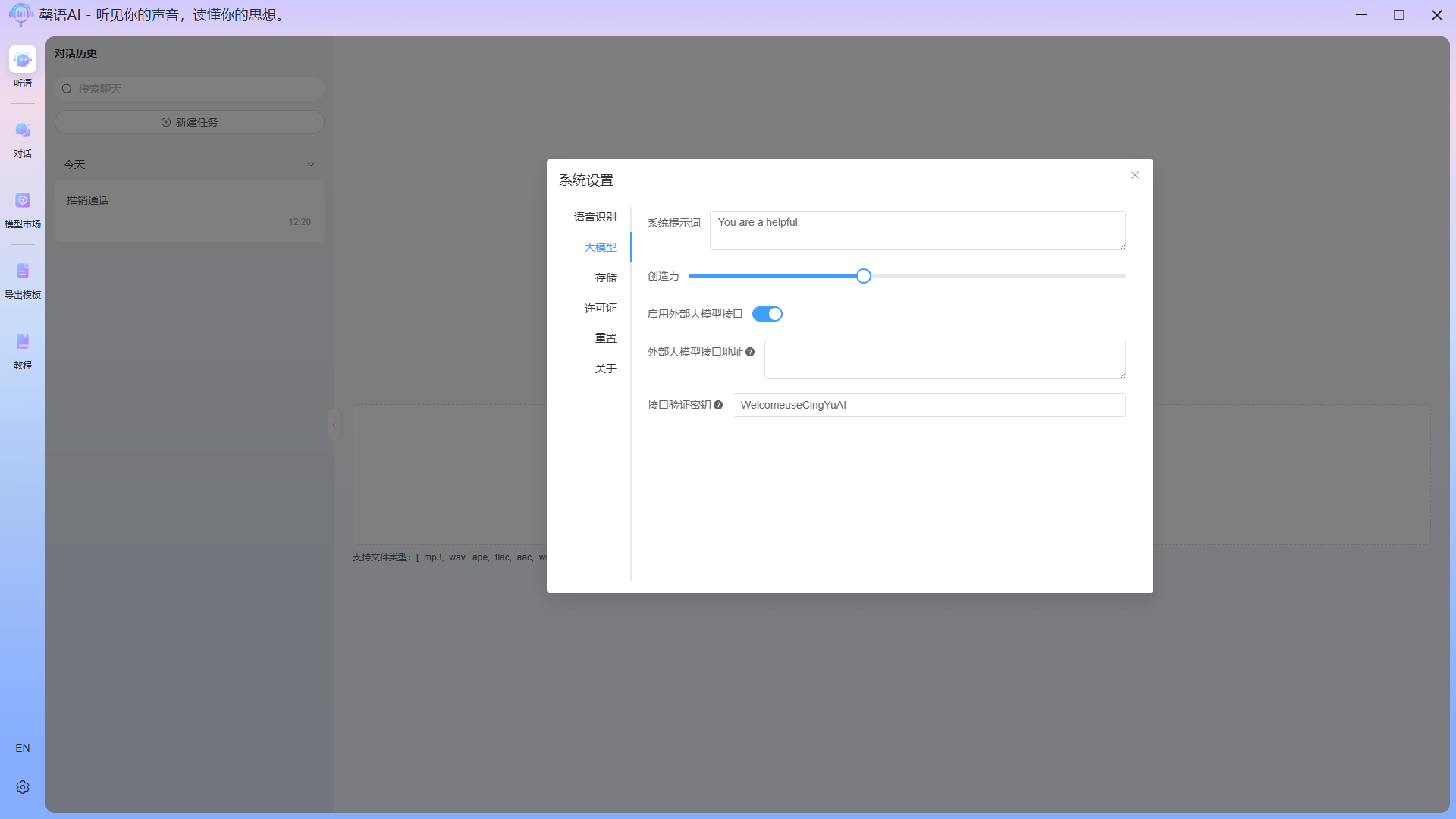
配置项说明:
- 系统提示词:与AI大模型对话时,使用的系统提示词,主要作用是设定AI身份、规定行为边界、控制输出风格、提供上下文信息等。若不清楚怎么编写,请不要随意更改。
- 创造力:设置AI在生成内容时的想象力,设置越小,输出的内容越固定,反之亦然。
- 启用外部大模型接口:当需要使用外部API接口与模型对话时,启动这个配置项,并填写好相应的外部大模型接口地址(baseUrl)和接口验证密钥(apiKey)。外部大模型接口仅支持OpenAI类接口。
- Host:启动大模型对话服务使用的主机名,请谨慎修改。
- 端口:启动大模型对话服务使用的端口号,请谨慎修改。
- 接口验证密钥:与大模型对话时,使用的密钥。
- GPU加速:开启GPU加速,可大幅度提升模型生成内容的效率,需要设置支持vulkan。
- 模型装载到GPU的层数:此项为CPU+GPU混合推理或完全GPU推理的配置项,-1/0/大于模型层数的值均为全GPU推理。数字的多少即多少层神经网络放到GPU,若您的GPU资源有限,可以根据您的情况尝试设置后进行测试,最终得出适合您的最佳值。
- 上下文长度:大模型生成内容时的上下文长度(上下文长度 = 输入内容 + 历史内容 + 生成内容,当长度超出设定时,模型报错),设置越大占用的显存越多,默认设置4K。
- 置kv缓存至内存:把模型的kv缓存数据放到内存上,可降低显存使用率,但会降低模型生成内容的速度。kv缓存的大小与上下文长度有关,上下文长度越大,kv缓存越大。
- 最大空闲时间(分钟):本地大模型后台最大空闲时。当不使用大模型功能的时间超出当前设定值时,应用将会自动释放掉后台的大模型服务资源。
存储
存储设置可修改模型的存储目录、临时文件目录,磁盘空间不足时,还可以清空临时文件。 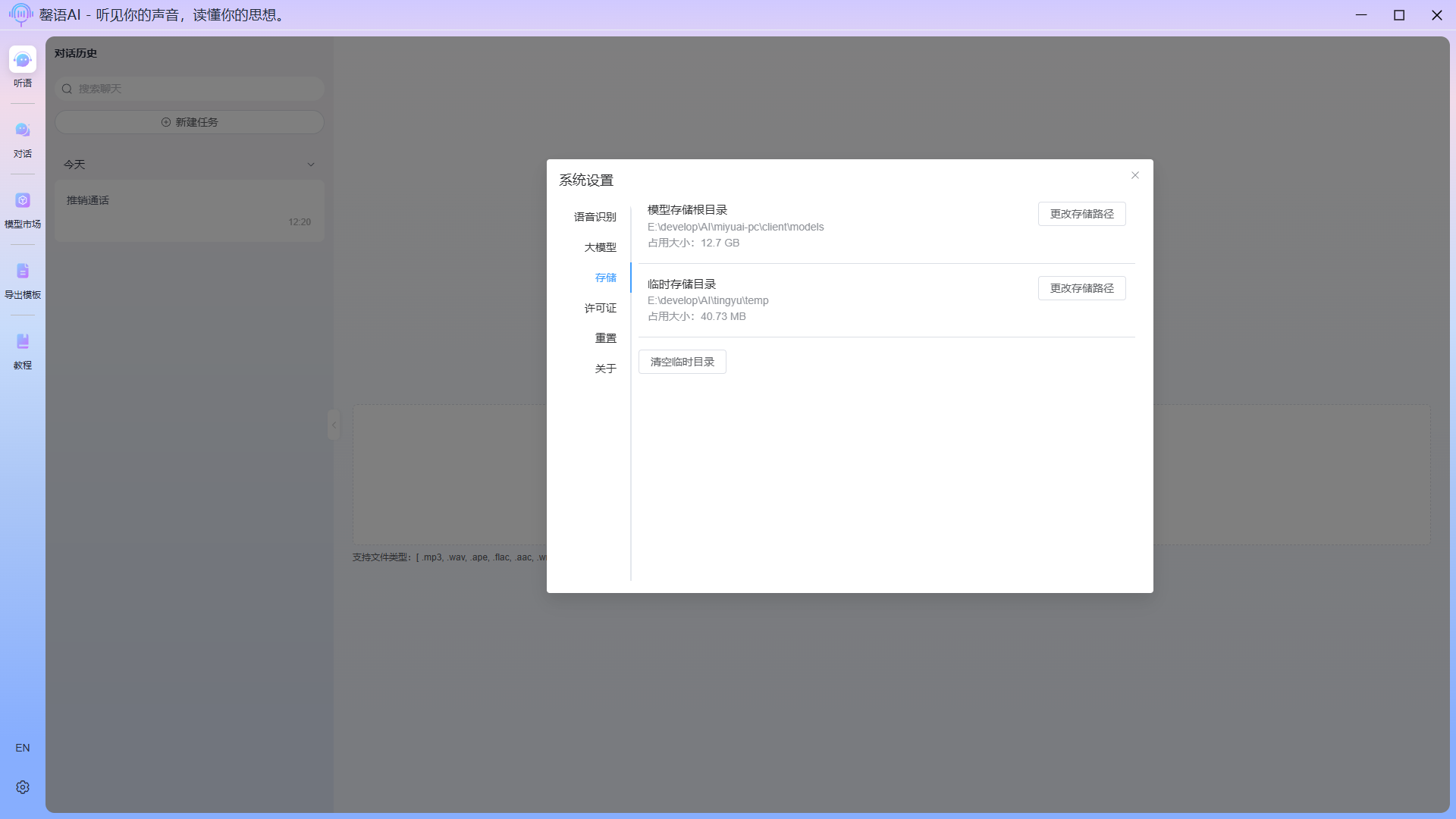
许可证
展示当前设备的许可信息与对应许可版本的功能差异。 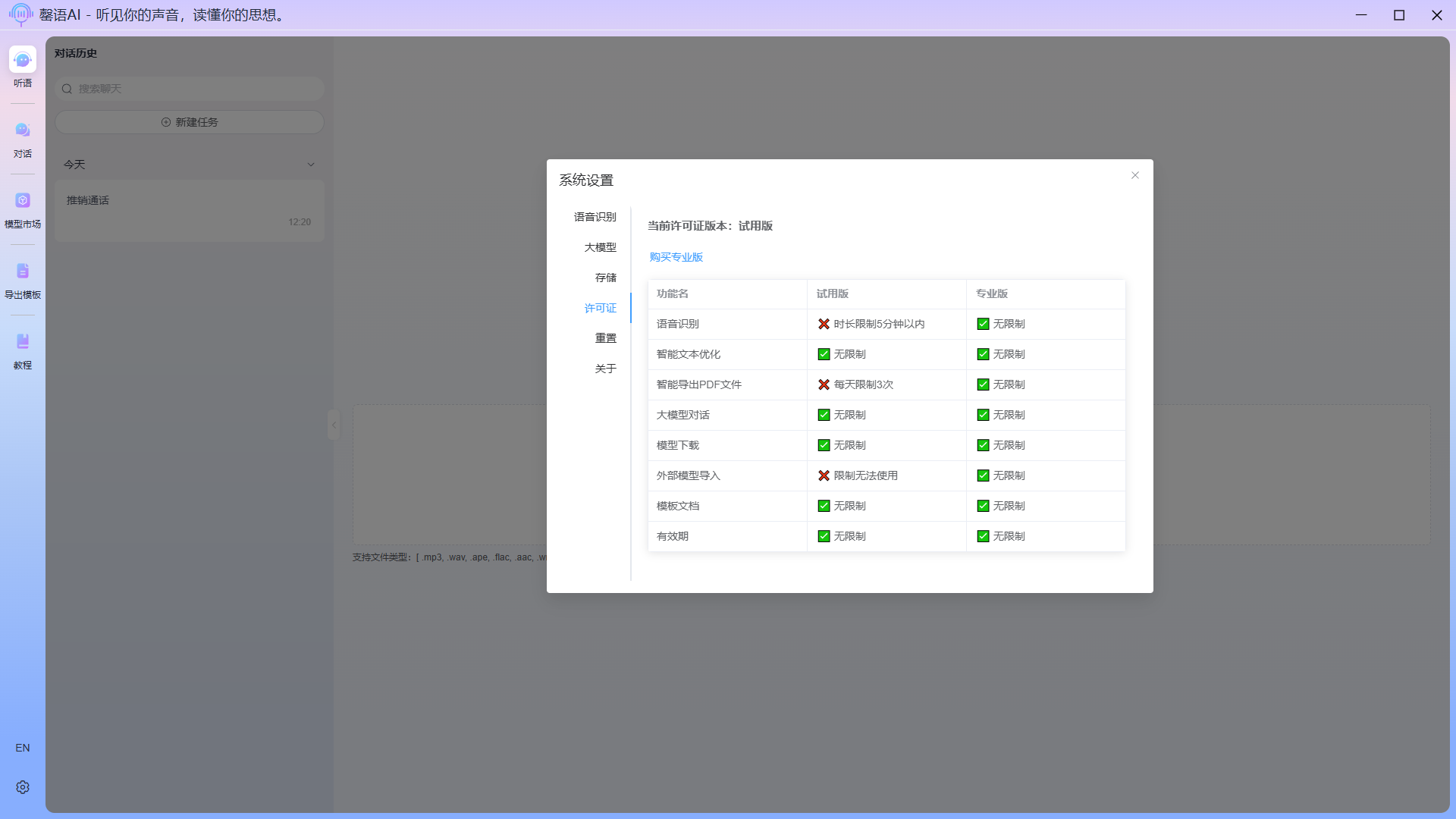
重置
点击重置系统配置后,可以还原系统配置至初始状态,并自动重启应用。 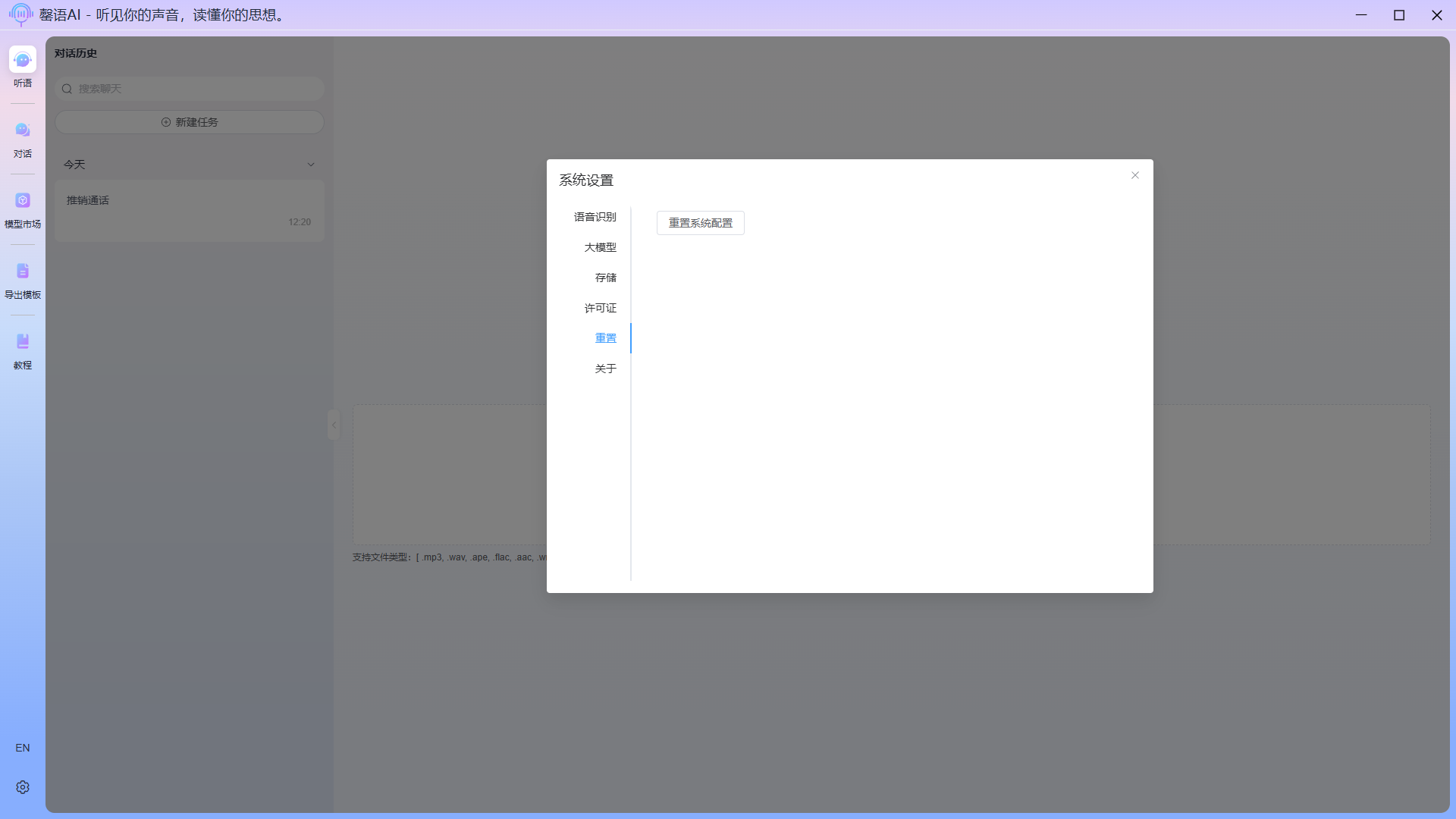
关于
此页展示应用版本号、官网地址等相关信息